The Browser High-Level Architecture
Introduction
The web browser basically consists of the following components:
- User Interface and UI Backend
- Browser Engine (it can be thought of as the controller that manages the rendering process, networking, user inputs, and other interactions)
- Rendering Engine
- JS Engine
- Networking
- Data Storage
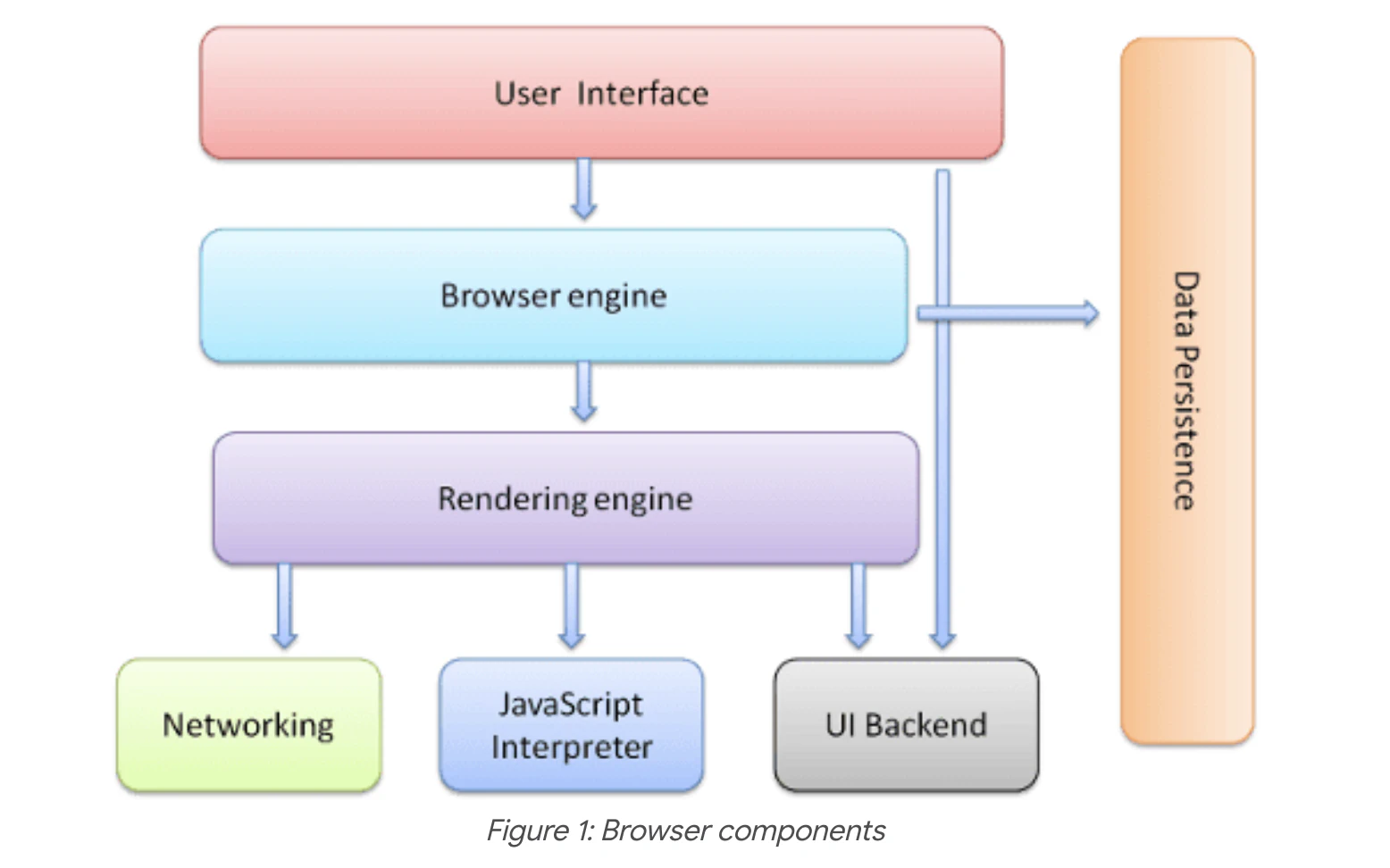
The browser engine marshals actions between the UI and the rendering engine. The rendering engine is responsible for displaying requested content.
The terms “browser engine” and “rendering engine” are often used interchangeably in many contexts, but they can also be viewed as distinct components depending on the level of detail in the architectural description.
The rendering engine is a more specific term that refers to the component within the browser engine that deals with rendering web pages. It takes the parsed content (HTML, CSS) and renders it visually on the screen.
- Examples in Practice
- Blink: In Chrome, Blink serves as both the browser engine and the rendering engine.
- Gecko: In Firefox, Gecko serves a similar dual role.
- WebKit: In Safari, WebKit functions as both the browser engine and rendering engine.
The networking component is used for network calls such as HTTP requests.
The UI Backend focuses on drawing basic widgets (combo boxes and windows), finally the browser may need to save all sorts of data locally, such as cookies. Browsers also support storage mechanisms such as localStorage, IndexedDB. We’ll cover the JS Engine later by introducing the V8 JavaScript Engine.
These components work together to provide a seamless browsing experience. When a user enters a URL, the following steps typically occur:
- User Input: The user types a URL into the address bar.
- Network Request: The browser engine makes a network request for the content.
- Content Fetching: The networking component fetches the HTML document.
- HTML Parsing: The rendering engine parses the HTML and requests additional resources like CSS, JavaScript, and images.
- CSS and JavaScript Execution: The rendering engine applies CSS to style the content, and the JavaScript engine executes any scripts.
- Content Display: The rendering engine constructs the layout and paints the visual representation on the screen.
- User Interaction: The user interacts with the page, which may trigger additional JavaScript execution and updates to the displayed content.
User Interface
The UI (User Interface) backend in a web browser is responsible for rendering and managing the visual elements that users interact with directly. This includes browser chrome such as the address bar, back/forward buttons, tabs, menus, and other interface components. Additionally, the UI backend ensures a responsive and user-friendly experience by handling user interactions and coordinating with other browser components like the rendering engine and networking stack.
- Rendering the Browser’s User Interface
- Handling User Interactions
- Window and Tab Management
- Integration with the Operating System
- Ensuring Performance and Optimization
- Accessibility
Browser’s most common UI Elements:
- Address Bar: Where users enter URLs.
- Navigation Buttons: Back, forward, refresh, and home buttons.
- Tabs: For managing multiple web pages within a single window.
- Menus and Toolbars: For accessing browser features and settings.
- Status Bar: Displays loading status, security information, etc.
The UI backend leverages the operating system’s graphics libraries (e.g., Win32 on Windows, Cocoa on macOS, GTK on Linux) to render these elements. Uses these libraries to ensure that the browser’s UI matches the native look and feel of the operating system.
One of the key functionality is handling user interactions. The browser captures user inputs such as clicks, keystrokes, mouse movements, and touch gestures, and then processes these events to perform actions like navigating, opening/closing tabs, scrolling, etc.
The UI Backend then determines how events are propagated through the UI components and the web content, and manages focus and ensures the correct component handles each event. That would lead to updating the UI in response to user actions. For example, updating the address bar when navigating to a new page or changing the active tab.
UI management includes managing browser windows, including opening, closing, resizing, and maximizing/minimizing windows, handling the creation, closure, and switching of tabs within a browser window. Managing tab-related features like tab previews, grouping, and pinning.
The browser uses the OS’s native UI toolkits for rendering and managing UI elements. Integrates with system-level services like notifications, context menus, and drag-and-drop operations. Interacts with system services for functionalities like updating the window title, managing system clipboard, and handling file dialogs.
Most of the browsers use GPU acceleration for rendering complex UI elements and animations to ensure smooth performance, and tries to minimize unnecessary redraws and reflows of UI elements to enhance performance, which could include techniques like incremental rendering to optimize the rendering process or delaying the initialization of non-critical UI components until they are needed to improve startup performance.
- Examples of UI Backends in Browsers
Note: this info could be outdated
- Chromium-based Browsers (Chrome, Edge, Opera): Use the Aura UI framework, which is part of the Chromium project, to render the UI across different platforms.
- Firefox: Uses the Photon UI framework, which builds on XUL (XML User Interface Language), for defining and rendering UI elements.
- Safari: Leverages the Cocoa framework on macOS for native UI rendering and management.
Rendering Engine
Besides “browser engine”, two other related terms are commonly used: “layout engine” and “rendering engine”. In theory, layout and rendering (or “painting”) could be handled by different engines. In practice, however, these components are tightly coupled and rarely encountered on their own outside of the browser engine. src: Browser engine - Wikipedia
The rendering engine’s primary role is to:
- Parse HTML, CSS, and other web content.
- Construct the DOM and CSSOM (CSS Object Model).
- Execute JavaScript (in collaboration with the JavaScript engine).
- Perform layout calculations to determine the geometry of elements.
- Paint the elements to the screen.
- Handle compositing to produce the final visual output.
HTML Parsing
- Tokenization: The HTML parser reads the HTML content and converts it into tokens.
- Tree Construction: These tokens are then used to build the DOM tree, which represents the structure of the document.
CSS Parsing
- CSSOM Construction: CSS files and style elements are parsed to create the CSSOM tree, representing all the styles applied to the document.
JavaScript Execution
- Integration with JavaScript Engine: JavaScript is executed by the JavaScript engine (e.g., V8 in Chrome), which can manipulate the DOM and CSSOM dynamically.
Render Tree Construction
- Combining DOM and CSSOM: The DOM and CSSOM trees are combined to create the render tree. The render tree consists of visual elements that need to be displayed on the screen, excluding non-visual elements (e.g., script tags).
Layout (Reflow)
- Calculating Positions and Sizes: The rendering engine calculates the position and size of each element in the render tree. This step is called layout or reflow. It ensures every element is placed correctly in the viewport.
Painting
- Rendering Pixels: The rendering engine converts the render tree into pixels. This step involves drawing text, images, colors, borders, shadows, etc., to the screen.
Compositing
- Layer Management: Modern browsers use compositing layers to manage different parts of the page separately. Layers are combined to produce the final image. This process helps in optimizing rendering performance, especially for animations and complex layouts.
Render Process in Detail
- The HTML parser reads the HTML document and converts it into the DOM tree.
- This involves handling various tags, attributes, and nested elements to build a hierarchical structure.
- CSS is parsed to create the CSSOM tree, which details the styles for each element.
- This involves interpreting selectors, properties, and values.
- The render tree is built by combining the DOM and CSSOM trees.
- It includes only the visible elements, ensuring that non-visual elements like script tags are excluded.
- Each node in the render tree corresponds to a box that will be displayed on the screen.
- The rendering engine calculates the exact position and size of each element in the render tree.
- This step considers the dimensions, margins, paddings, borders, and positioning properties.
- Reflow can be an expensive operation, especially if it needs to be recalculated frequently.
- The render tree is traversed, and each node is painted to the screen.
- This involves drawing the visual representation of each element, including text, colors, images, etc.
- The page is divided into layers, and each layer is rendered independently.
- These layers are then composited to form the final image that appears on the screen.
- Compositing helps in improving performance, especially for complex layouts and animations.
- Rendering engines employ several techniques to optimize performance:
- Incremental Layout and Painting: Avoiding full-page reflows and repaints whenever possible.
- Hardware Acceleration: Utilizing the GPU to offload some of the rendering tasks.
- Lazy Loading: Deferring the loading of non-critical resources.
- Caching: Storing computed styles and layout information to speed up rendering.
Common Rendering Engines
| Blink: Used by Google Chrome and other Chromium-based browsers like Microsoft Edge (since version 79). | Blink (Rendering Engine) |
| WebKit: Used by Safari. | WebKit project home |
| Gecko: Used by Mozilla Firefox. | GitHub Gecko Repo |
| EdgeHTML: Used by Microsoft Edge (legacy version). | EdgeHTML - Wikipedia |
| Trident: Used by Internet Explorer. (not supported) | Trident - Wikipedia |
- Excerpt from Wikipedia on notable engines
- Apple created the WebKit engine for its Safari browser by forking the KHTML engine of the KDE project.[8] All browsers for iOS must use WebKit as their engine.[9]
- Google originally used WebKit for its Chrome browser but eventually forked it to create the Blink engine.[10] All Chromium-based browsers use Blink, as do applications built with CEF, Electron, or any other framework that embeds Chromium.
- Microsoft has two proprietary engines, Trident and EdgeHTML. Trident, also called MSHTML, is used in the Internet Explorer browser. EdgeHTML, being a fork of Trident, was the original engine of the Edge browser (now called Edge Legacy); it’s still found in some UWP apps.[11] The new, Chromium-based Edge was remade with the Blink engine.[12]
- Mozilla develops the Gecko engine for its Firefox browser and the Thunderbird email client.[2]
Read more at https://en.wikipedia.org/wiki/Browser_engine#Notable_engines
For further reading: How Blink works
Networking
Networking within a browser is a crucial component responsible for fetching resources from the web. This involves handling HTTP/HTTPS requests, managing connections, caching resources, and more. Here’s an in-depth look at the networking process within a web browser:
The primary role of the browser’s networking component is to:
- Fetch HTML documents, CSS, JavaScript, images, videos, and other resources.
- Handle various protocols such as HTTP, HTTPS, FTP, etc.
- Manage connections efficiently to optimize performance.
- Implement caching mechanisms to reduce load times.
- Ensure security through secure connections and certificate validation.
Key Components and Processes
Resource Fetching
- URL Parsing: When a user enters a URL, the browser parses it to understand the protocol, domain, path, and query parameters.
- DNS Resolution: The domain name is resolved to an IP address using the Domain Name System (DNS).
- Establishing a Connection: Depending on the protocol (HTTP/HTTPS), a connection is established. For HTTPS, a secure SSL/TLS handshake is performed.
HTTP/HTTPS Requests
- Request Construction: The browser constructs an HTTP request, including method (GET, POST, etc.), headers, cookies, and any data payload.
- Sending the Request: The request is sent over the established connection to the server.
- Receiving the Response: The server responds with an HTTP response, including status code, headers, and the requested resource.
Caching
- Browser Cache: The browser stores copies of resources in the local cache to reduce load times for subsequent requests.
- Cache Control: HTTP headers like Cache-Control, Expires, and ETag are used to manage caching behavior.
- Conditional Requests: The browser can make conditional requests using headers like If-Modified-Since or If-None-Match to check if the resource has changed.
Resource Loading
- Blocking vs. Non-blocking: Scripts and stylesheets can block rendering. The browser optimizes loading by determining the critical path and loading resources asynchronously when possible.
- Priority Loading: Critical resources (e.g., CSS for above-the-fold content) are loaded with higher priority.
Security
- SSL/TLS Handshake: For HTTPS, the browser performs an SSL/TLS handshake to establish a secure connection.
- Certificate Validation: The browser verifies the server’s SSL certificate to ensure the connection is secure and trusted.
- Mixed Content: Browsers block or warn against mixed content (e.g., loading HTTP resources on an HTTPS page).
Detailed Workflow Example
- The user enters a URL in the address bar.
- The browser parses the URL and determines the protocol, domain, path, and query parameters.
- The browser checks the DNS cache. If the IP address is not cached, it performs a DNS lookup to resolve the domain to an IP address.
- HTTP Connection: For HTTP, a TCP connection is established to the server.
- HTTPS Connection: For HTTPS, a TCP connection is established, followed by an SSL/TLS handshake to create a secure connection.
- The browser constructs an HTTP request with the appropriate method (GET, POST, etc.), headers, cookies, and any necessary data payload.
- The request is sent to the server over the established connection.
- The server responds with an HTTP response, including a status code (e.g., 200 OK, 404 Not Found), headers, and the requested resource.
- The browser processes the response. If the resource is an HTML document, it begins parsing and may initiate additional requests for linked resources (e.g., CSS, JavaScript, images).
- The browser stores the resource in the cache, subject to cache control headers.
- For subsequent requests, the browser checks the cache. If a cached copy is available and valid, it is used instead of fetching from the network.
- The browser can make conditional requests to check if the resource has changed, reducing unnecessary data transfer.
- SSL/TLS Handshake: For HTTPS connections, the browser and server exchange keys and negotiate encryption parameters to establish a secure connection.
- Certificate Validation: The browser checks the server’s SSL certificate against trusted certificate authorities (CAs) to ensure authenticity and integrity.
- Mixed Content Handling: The browser identifies and handles mixed content, blocking insecure requests on secure pages.
- Performance Optimization
- HTTP/2 and HTTP/3: Newer HTTP protocols that improve performance through multiplexing, header compression, and faster connection establishment.
- Keep-Alive: Reusing a single TCP connection for multiple HTTP requests to reduce overhead.
- Prefetching and Preloading: The browser can prefetch resources that are likely to be needed soon or preload resources to ensure they are available when required.
- Lazy Loading: Deferring the loading of non-critical resources until they are needed.
Data Storage
The data storage component of a web browser is responsible for storing various types of data locally on the user’s device. This data includes cookies, local storage, session storage, IndexedDB, cache storage, and other forms of persistent and temporary data. This component ensures that web applications can save and retrieve data efficiently, enhancing the user experience by enabling features like offline access, personalized settings, and faster load times.
Key Types of Data Storage
- Cookies
- Web Storage
- IndexedDB
- Cache Storage
- File System Access API
- Service Workers and Offline Storage
- Store small pieces of data sent from a website and stored on the user’s device.
- Used for session management, personalization, and tracking user activity.
- Limited in size (typically around 4KB).
- Can be set to expire at a specific time or persist until the browser is closed.
- Sent with every HTTP request to the domain that set the cookie.
- Both have a larger storage capacity than cookies (typically around 5-10MB per origin).
- Simple key-value pair storage.
- Local Storage:
- Stores data with no expiration time.
- Persistent across browser sessions.
- Typically used for storing settings and preferences.
- Session Storage:
- Stores data for the duration of the page session.
- Data is cleared when the page session ends (e.g., when the tab is closed).
- Used for temporary data needed only for a single session.
- Provides a way to store large amounts of structured data.
- Supports complex queries and transactions.
- Asynchronous API for performing database operations.
- Stores data in object stores, which are similar to tables in a relational database.
- Can handle binary data (e.g., images, files).
- Useful for offline applications that need to store large datasets.
- Stores network requests and their corresponding responses.
- Enables faster load times by serving cached responses.
- Part of the Service Workers API.
- Allows web applications to cache assets (HTML, CSS, JavaScript, images, etc.).
- Supports custom caching strategies (e.g., cache-first, network-first).
- Provides a way for web applications to read and write files and directories on the user’s local file system.
- Allows direct access to files and directories with user consent.
- Enables advanced use cases like editing and saving local files directly from the web application.
- Background scripts that intercept and handle network requests.
- Enable offline capabilities by caching resources and serving them when offline.
- Run independently of web pages.
- Can cache resources and handle network requests even when the network is unavailable.
- Same-Origin Policy: Ensures that data stored by one origin (domain) cannot be accessed by another origin.
- HTTPS: Sensitive data should be stored and accessed over secure connections to prevent interception.
- Permissions and User Consent: Some APIs (e.g., File System Access API) require explicit user consent to access data.
- Data Encryption: Encrypt sensitive data before storing it locally to enhance security.
- Storage Limits: Be mindful of storage limits imposed by browsers to avoid quota exceeded errors.
- Efficient Data Access: Use appropriate storage mechanisms (e.g., IndexedDB for complex queries) to ensure efficient data access and manipulation.
- Caching Strategies: Implement effective caching strategies to balance performance and freshness of data.